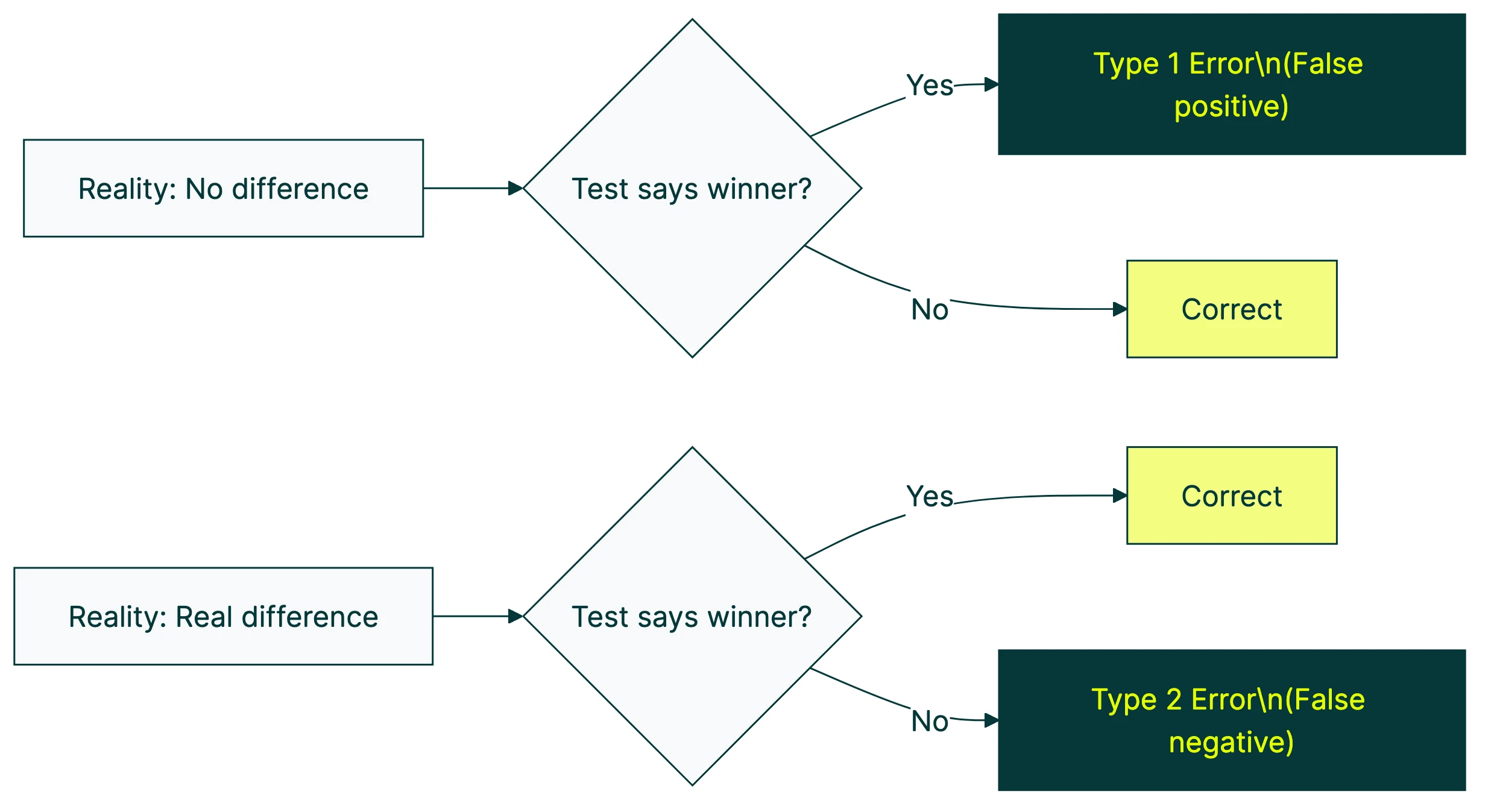
A type 1 error means your A/B test says “we have a winner” when there’s no real difference. A type 2 error means your test says “nothing happened” when there actually was a winner hiding in the data.
Both cost you money. One makes you ship changes that don’t work. The other makes you throw away changes that do. Understanding them is a key part of A/B testing and testing methodology. The sample size calculator helps you plan tests that minimize both, and the significance calculator checks your results when the test ends.
The tricky part? Most teams only worry about type 1 errors (false winners). They ignore type 2 errors entirely. And the numbers show that common A/B testing mistakes make both errors far more likely than you think.
What is a type 1 error in A/B testing?
Picture this. You test a new button color on your pricing page. After four days, your dashboard shows a 15% lift in signups. You celebrate, push it live, and… nothing changes. Signups stay flat.
That’s a type 1 error. Your test found a pattern in the noise.
The standard rule is to accept a 5% chance of this happening. Statisticians call this your “alpha” level, and it goes back to Ronald Fisher in 1925. He picked the 1-in-20 threshold because it was, in his own words, “convenient.” Not optimal. Not proven. Convenient.
That matters because the whole industry treats 95% confidence like a law of physics. It’s not. It’s a rule of thumb a statistician picked for farming experiments a hundred years ago.
When your A/B test reaches 95% confidence, you’re saying: “I accept a 1-in-20 chance this result is fake.” That’s the deal you make before you start. You can find your p-value to see exactly where your test lands against that threshold.
Our take: A 5% false positive rate sounds small. It’s not. Run 20 tests a year (which is modest), and on average, one “winner” is fake. Ship that fake winner, and you’ve just made your site worse while thinking you made it better.
What is a type 2 error in A/B testing?
You test a trust badge on your checkout page. Your conversion rate is 3.2%. The trust badge actually lifts it to 3.5%. That’s real. That’s money.
But your test only ran for two weeks. With your traffic, you needed four weeks to detect a difference that small. So the dashboard says “no significant difference.” You pull the badge and move on.
You just threw away a real improvement. That’s a type 2 error.
The standard convention is 80% statistical power. That means you accept a 20% chance of missing a real winner. Running a power analysis for A/B tests before you start tells you exactly how many visitors you need to hit that 80% mark. One in five genuine improvements, gone. And most teams don’t even know they lost them because a false negative looks exactly like “the test didn’t work.”
Type 1 errors are visible. You ship a bad change, metrics drop, someone notices. Type 2 errors are invisible. Nobody sends a Slack message saying “hey, we just missed a winner we never knew about.”
That’s what makes them dangerous.
Type 1 vs type 2 error: side-by-side comparison
Here’s the quick reference:
| Type 1 error | Type 2 error | |
|---|---|---|
| Plain English | False winner | Missed winner |
| What happens | You ship a change that doesn’t actually work | You discard a change that would have worked |
| Nickname | False positive | False negative |
| Greek letter | Alpha (α) | Beta (β) |
| Standard threshold | 5% (95% confidence) | 20% (80% power) |
| Business cost | Wasted dev time, possible conversion drop | Lost revenue from improvements you’ll never know about |
| Main cause | Peeking at results, too many metrics | Not enough traffic, test too short |
| How to reduce | Don’t peek, fewer metrics, stricter threshold | More visitors, bigger changes to test, longer tests |
These two errors sit on opposite ends of a seesaw. Making one less likely makes the other more likely. If you tighten your confidence threshold from 95% to 99%, you’ll catch fewer false winners. But you’ll also miss more real ones because your test needs more data to clear the higher bar.
The accepted balance is 95% confidence with 80% power. It’s a reasonable starting point for most split testing programs, but it’s not gospel — and the frequentist approach to statistics isn’t the only option. Getting your control group design right matters just as much as picking the right thresholds.
The answer depends on what’s more expensive for your business. If shipping a bad change costs thousands in development and customer churn, worry more about type 1 errors. If you’re running quick headline tests where the downside is low, worry more about type 2 errors, because you’re probably leaving money on the table.
Why your 5% false positive rate isn’t really 5%
Most articles stop here. They explain the 5% number and move on. It’s actually worse.
The peeking problem. You know that urge to check your test results every day? Every time you peek and consider stopping, you’re inflating your false positive rate. Evan Miller calculated that with regular peeking, the actual false positive rate jumps to 26.1%. That’s not 1 in 20. That’s closer to 1 in 4.
Netflix proved it. They ran simulations where both versions were identical (called an A/A test, where there’s literally no difference to find). Using a peeking strategy, 66 out of 100 tests falsely declared a winner. Two thirds. From tests where nothing had changed. You can use A/A testing to check your false positive rate before trusting any real test results from your setup.
Think about that. If you check results daily and stop when something looks good, your “95% confidence” is actually closer to 34% confidence.
The multiple comparisons problem. Say you test 4 button variations and track 25 metrics. That’s 100 comparisons. At a 5% false positive rate per comparison, you should expect 5 false positives by pure chance. One of your metrics will almost certainly show a “winner” that isn’t real.
Fishing for patterns in the data. Researchers call it “p-hacking.” It means you keep slicing and rearranging your data until something looks significant. University of Pennsylvania researchers studied four common tricks. Choosing when to stop collecting data. Cherry-picking which metrics to report. Adding filters after the fact. Comparing only the groups that look good. Using just those four tricks, the false positive rate hit 61%. And these shortcuts happen in A/B testing every day. Someone says “let’s also check mobile visitors separately” after the test is running. That’s p-hacking.
David Colquhoun from University College London put it bluntly: at p=0.05 with typical statistical power, “you will be wrong at least 30% of the time.”
So if you’ve ever peeked at results early, tracked multiple metrics, or sliced data after the fact, your actual type 1 error rate was nowhere near 5%. Keep in mind that bandit algorithms inflate false positives in a similar way, because shifting traffic toward a “winner” mid-test introduces selection bias that can amplify noise.
Our take: This is why we built Kirro with math that works differently (called Bayesian statistics). Instead of a binary “significant or not” verdict, you see the probability that Version B is actually better. It’s more forgiving of peeking, and it tells you in plain English when the data isn’t strong enough yet.
The hidden cost of type 2 errors: missed winners nobody notices
Everyone worries about shipping a fake winner. Almost nobody worries about discarding a real one. And the data says the second problem is bigger.
Microsoft’s experimentation team found that only about a third of ideas they tested actually moved the needle. At Google and Bing, where the product is already highly refined, only 10 to 20% of tests produce positive results.
Now think about what happens if your tests are underpowered (not enough visitors). With 80% power, you already miss 1 in 5 real effects. Drop to 50% power (common for sites with less traffic) and you’re missing half your real winners. They look like “no result” in your dashboard, and you move on.
The most famous example: a low-priority Bing headline change was nearly shelved. Nobody thought it mattered. It ended up generating over $100 million in annual US revenue. If the test had been underpowered and returned “no significant difference,” that money would have stayed on the table forever.
And even when you do catch a winner, your reported lift is probably inflated. It’s called the winner’s curse. If your test says “+20% conversion rate,” the real improvement is likely closer to +10%. This isn’t theoretical. Etsy, Amazon, and Airbnb all built automated correction tools into their testing platforms. The effect was large enough to distort real product decisions.
For smaller teams running CRO testing programs, the lesson is simple: be suspicious of very large reported lifts, and don’t discard tests just because they came back “flat.”
How to reduce both types of errors in your A/B tests
Don’t peek and stop early. Decide your visitor count before you start. Let the test run until it gets there. Calculate your sample size upfront so you know what you’re committing to.
Every additional version or metric you track multiplies your false positive risk. Stick to one change at a time. If you need to test multiple things at once, you need more traffic to keep the math honest.
Make sure you have enough traffic. Underpowered tests are the top cause of type 2 errors. If your site gets 500 visitors a week, don’t test subtle shade-of-blue button changes. Test something big enough to detect with the traffic you have. If you’re split testing your landing pages, make the variations meaningfully different.
Also check your traffic split. Ron Kohavi, who led experimentation at Microsoft, found that 6 to 10% of A/B tests are completely invalid. The cause is something called sample ratio mismatch: the actual visitor split doesn’t match what you set. You aimed for 50/50 but got 55/45. Now both error types become more likely.
Before you start, pick one primary metric. Write down what counts as a win. This stops you from “finding” patterns in noise after the fact.
And if peeking is your weakness, try Bayesian A/B testing. Traditional testing gives you a binary pass/fail. Bayesian gives you probability: “Version B has an 89% chance of being better.” It’s more forgiving of checking early, and it works better with smaller traffic. Kirro uses this approach. You see confidence levels in plain English, not p-values. Try it free and see the difference.
If you’re choosing between A/B testing tools, check how they handle these problems. The tool should do the hard math for you, not just hand you a spreadsheet and say “good luck.”
FAQ
What is a type 1 error in A/B testing?
A type 1 error is a false positive. Your test declares Version B the winner, but the difference was just random noise. You ship the change thinking it works, but it doesn’t actually improve anything. In stats language, you rejected the null hypothesis (the assumption that nothing changed) when you shouldn’t have. The standard accepted rate is 5%. In practice, it’s often much higher because of peeking, tracking too many metrics, and stopping tests early.
What’s the difference between type 1 and type 2 errors?
Type 1 is a false alarm. You think something changed, but it didn’t. Type 2 is a missed signal. Something actually changed, but your test didn’t catch it.
Type 1 errors lead you to ship changes that don’t work. Type 2 errors lead you to throw away changes that would have worked. Both cost money, but type 2 errors are harder to spot because they look exactly like “the test had no result.”
How do you avoid type 2 errors?
Four practical steps. Get more traffic to your test, or test bigger changes so the improvement is easier to spot. Run tests for the full planned duration. Aim for at least 80% statistical power when you plan your sample size. And don’t give up on ideas just because one short test came back flat.
If your site doesn’t get enough traffic for traditional testing, Bayesian A/B testing can help. Instead of asking “is it statistically significant?” (binary yes/no), it asks “how likely is Version B to be better?” That works with smaller samples.
What is the relationship between type 1 and type 2 errors?
They’re on a seesaw. Making one less likely makes the other more likely (unless you increase your traffic).
If you tighten your confidence threshold from 95% to 99%, you’ll have fewer false winners (fewer type 1 errors). But your test now needs more data to clear that higher bar. So you’ll miss more real winners (more type 2 errors). The only way to shrink both at once: more visitors.
Is Bayesian testing immune to peeking?
No. But it handles it differently. Traditional testing makes a binary decision (significant or not), and every time you peek, you’re adding chances for a false positive. Bayesian testing updates its beliefs continuously and gives you a probability rather than a yes/no verdict. That makes it more forgiving of peeking, but it’s not foolproof with tiny sample sizes. Try it yourself and you’ll see the difference. Instead of “p < 0.05,” you get “Version B has an 89% chance of being better.” Much easier to act on.
Which error is worse, type 1 or type 2?
It depends on what you’re testing. For expensive changes (a full site redesign, a new checkout flow), type 1 errors are scarier. You invest heavily in shipping something that doesn’t work. For low-cost tests (headline swaps, button text, small conversion tweaks), type 2 errors probably cost you more over time. You’re repeatedly throwing away easy wins because your tests aren’t powerful enough to catch small improvements.
Most teams default to worrying about type 1 errors because those are visible. But the silent pile of missed winners from type 2 errors could easily add up to more lost revenue. Think about how much sequential testing or longer test durations might save you before tightening your significance threshold even further.

Randy Wattilete
CRO expert and founder with nearly a decade running conversion experiments for companies from early-stage startups to global brands. Built programs for Nestlé, felyx, and Storytel. Founder of Kirro (A/B testing).
View all author posts