A multi-armed bandit is an algorithm that automatically sends more traffic to whichever version of your page is winning. Instead of splitting visitors 50/50 and waiting weeks for a result, the algorithm learns as it goes. It shifts traffic toward the better performer in real time.
Sounds like a no-brainer upgrade over standard A/B testing, right?
Not so fast. Bandits trade statistical confidence for speed. And for most small businesses testing two or three versions of a headline, that trade isn’t worth it. A well-designed A/B test with solid testing methodology will give you a more reliable answer in the same amount of time.
But there are situations where bandits genuinely shine. Bandits are just one of several other alternatives to traditional A/B testing, each with its own strengths. Real research backs up both sides. Vendor marketing doesn’t tell you the full story.
What is a multi-armed bandit?
The name comes from slot machines. Old-school slot machines had one arm (the lever you pull), so gamblers called them “one-armed bandits.” Now imagine standing in front of a whole row of them. Each one pays out at a different rate, but you don’t know which is which.
Your goal: figure out the best machine while losing as little money as possible on the bad ones.
That’s the multi-armed bandit problem. Try enough machines to learn which one is best (exploration), but don’t waste too much money on losers along the way (exploitation).
In website testing, the “machines” are versions of your page. The “payout” is conversions. The algorithm tries each version, watches what happens, and gradually funnels more visitors to the one that’s converting best.
The simplest distinction: A/B tests learn, then act. Bandits learn and act at the same time.
A regular A/B test shows Version A to 50% of visitors and Version B to the other 50%. It waits until it has enough data, then declares a winner.
A bandit starts the same way. But as soon as one version looks better, it sends more traffic there. Maybe 60/40. Then 70/30. Then 80/20.
The idea is that you “waste” fewer visitors on the losing version. That sounds smart. But it comes with trade-offs that most articles skip over.
If you’re new to testing in general, start with what split testing means before going deeper here.
How bandit algorithms work (without the math)
You don’t need to understand the math behind these algorithms. But knowing the three main flavors helps you evaluate what testing tools actually do under the hood.
Epsilon-greedy: the simple one
Pick a number, say 10%. That’s your exploration budget. The algorithm spends 10% of its traffic trying random versions. The other 90% goes to whichever version is winning right now.
It’s like going to your favorite restaurant 9 times out of 10, and trying somewhere new every 10th dinner. Simple. Predictable. Not very clever, but it works.
The downside? That 10% exploration never stops. Even after a million visitors, it’s still sending 10% to random versions. It doesn’t get smarter over time.
Upper confidence bound (UCB): the curious one
This algorithm favors the version it knows the least about. If Version C has been shown to 50 people while A and B have been shown to 5,000 each, UCB picks C. Not because it thinks C is better. Because it’s not sure yet.
Think of it like a food critic who tries the new restaurant in town before going back to the ones they’ve already reviewed.
Thompson sampling: the one most tools actually use
This is the approach behind most modern bandit implementations. It’s what Google used in their (now-defunct) Content Experiments. It uses Bayesian A/B testing math (rooted in the broader Bayesian vs frequentist statistics divide) to make an educated guess about which version is best, then tests that guess.
In plain language: instead of picking the version that looks best right now, it factors in how certain it is. A version with a 60% conversion rate from 20 visitors isn’t necessarily better than one with 55% from 2,000 visitors. Thompson Sampling understands that.
There’s also a more advanced version called contextual bandits. These consider who the visitor is (location, device, time of day) before picking which version to show. That’s website personalization territory. A whole different level of complexity. For a broader look at how machine learning is reshaping experimentation, our guide to AI A/B testing covers the full picture.
Our take: Most small businesses don’t need to know which algorithm their tool uses. What matters is understanding the trade-offs of bandits vs. A/B tests. The algorithm choice is a detail for the tool vendor to worry about.
Multi-armed bandit vs. A/B testing: what’s actually different
The comparison that matters:
| A/B test | Multi-armed bandit | |
|---|---|---|
| Traffic split | Fixed 50/50 | Shifts toward the winner |
| Goal | Statistical confidence (did it actually work?) | Fewer conversions “wasted” on losers |
| Duration | Fixed (you decide when it ends) | Continuous (runs until you stop it) |
| Best for | Understanding cause and effect | Picking winners fast when time is short |
| What you learn | Which version works and by how much | Which version appeared to work (with less certainty) |
| Number of metrics | As many as you want | One (the metric you’re optimizing) |
CXL put it well: A/B testing is for understanding. Bandits are for optimization. Those sound similar, but they’re genuinely different goals.
Understanding means you can explain why Version B won and apply that insight to your next ten tests. Optimization means you picked the winner and moved on, but you might not fully understand why it worked.
Ronny Kohavi ran experimentation at Microsoft, Airbnb, and Amazon. His take: the test period is tiny compared to the time after the test. Your winning headline might run for two years. The few weeks of “wasted” traffic during a 50/50 test? Rounding error.
But if the bandit picked the wrong winner (and they’re more prone to that), you run the wrong version for two years.
For most businesses doing landing page split testing, a clean A/B test with honest results is the better path. Sequential testing lets you call a winner early if you’re impatient, without sacrificing reliability.
When bandit testing actually makes sense
Bandits aren’t useless. They’re just specific. They genuinely outperform A/B tests in a few situations:
Short-lived campaigns. Running a 3-day Black Friday promotion with 5 different banner designs? A standard A/B test can’t reach confidence in 3 days. A bandit will at least route more traffic to the better-performing banners while the campaign runs. You might not know why one worked, but you’ll sell more during those 3 days.
Email subject lines. Some email platforms send a batch to a small sample first, then use a bandit to pick the winning subject line for the rest. The “test” lasts minutes. Feedback is immediate. You only care about opens. Near-perfect bandit use case.
The Washington Post built an internal system called “Bandito” for rotating news headlines. It converges on the best one automatically. Headlines are perishable (nobody cares which headline won yesterday), feedback is instant (clicks), and there’s one metric that matters.
Testing many versions at once. This is where the research gets interesting. A study from ACM SIGKDD 2022 found something surprising. With 3 or fewer versions, a well-designed A/B test finds the winner faster and more reliably. Bandits only pull ahead when you’re testing 4+ options at the same time.
Most small businesses test two versions. Version A vs. Version B. For that, you don’t need a bandit. You need a good A/B test and enough patience to let it finish.
Our take: If you’re testing fewer than 4 versions (and you probably are), skip bandits entirely. A Bayesian A/B test gives you faster reads than traditional testing without the downsides we’re about to cover.
When bandits don’t work (the parts nobody talks about)
This section is why we wrote this article. Every vendor page tells you bandits are faster and smarter. Almost none of them mention these problems.
The false positive problem
Here’s a stat you won’t find on any vendor’s blog. Run a bandit test using Thompson Sampling, then analyze the results with a standard statistical test. Your false positive rate (type 1 error) jumps from 5% to as high as 13%.
That’s from a 2021 paper on bandit data analysis. Practitioner Marton Trencseni confirmed it by running thousands of simulated tests on a computer (Monte Carlo simulations). Thompson Sampling produced a 9% false positive rate vs. 3.5% for fixed A/B tests.
What does that mean in plain language? About 1 in 8 “winners” from a bandit test isn’t actually better than the original. You think you found an improvement. You ship it. But the improvement was noise.
That doesn’t happen because bandits are broken. It happens because adaptive traffic allocation breaks the math. Standard statistical tests assume equal groups. When a bandit sends 80% of traffic to one version and 20% to another, those tests give you wrong answers.
Optimizing the wrong thing
Bandits optimize whatever metric you point them at. They’re obedient that way. The problem is, the obvious metric isn’t always the right one.
A study from Wharton and the University of Michigan (published in Marketing Science, the field’s top journal) tested this directly. A major display advertiser ran bandit-optimized campaigns. When they optimized for clicks, they got roughly 10% fewer actual customers compared to optimizing for conversions.
Clicks were cheap. Conversions were what mattered. The bandit cheerfully optimized the wrong thing.
This matters because bandits collapse your whole business outcome into a single number. You can’t tell a bandit “maximize signups, but keep page speed fast and bounce rate under 60%.” It does one thing. Pick the wrong thing, and you get exactly what you asked for. Nothing you wanted.
Understanding what to measure is half the challenge. Our guide on A/B testing conversion rates digs into choosing the right metric.
Changing visitor behavior
Every bandit algorithm assumes that conversion rates stay the same throughout the test. Monday visitors convert the same as Saturday visitors. January traffic behaves like March traffic.
That’s almost never true.
If your site gets business traffic on weekdays and casual browsers on weekends, the conversion rate shifts every few days. A bandit might declare Version B the winner on Wednesday. It shifts 80% of traffic there. Then it underperforms all weekend. By Monday, it course-corrects. But the data is already contaminated.
Sven Schmit, Head of Statistics Engineering at Eppo (an experimentation platform), puts it bluntly: “All best known bandit algorithms assume there are no time-varying effects and can get easily tripped up.”
Delayed conversions
Bandits assume that when someone sees a page, you know right away whether they converted. That works for clicks and email opens. It doesn’t work for most real business conversions.
Someone visits your SaaS landing page today. They sign up next Tuesday. The bandit spent a whole week making traffic decisions without knowing that visit led to a signup. It allocated traffic based on incomplete data.
If the path from visit to conversion takes days or weeks, bandits make choices they’d regret with full information. A standard A/B test doesn’t have this problem. It doesn’t make decisions during the test.
Amplified bugs
In a standard A/B test, a bug affects at most 50% of your traffic. The other half sees the original page. Built-in damage control.
A bandit can route near-100% of traffic to a broken version before anyone notices. Say a version has a subtle bug that inflates measured conversions. Maybe a broken checkout button counts clicks as “conversions.” The bandit will enthusiastically send everyone there.
In a study that interviewed 11 practitioners at 5 companies, researchers found that several teams abandoned bandits after exactly this kind of incident. The algorithm amplified problems that fixed-allocation tests would have contained.
The regret vs. rigor trade-off
In bandit research, “regret” has a specific meaning. It’s the gap between what you earned and what you would have earned if you’d sent all traffic to the best version from the start. Bandits minimize regret. That’s their whole job.
But researchers at MIT proved mathematically that reducing regret weakens your ability to detect whether a version actually works. Statisticians call that statistical power. You can’t improve both. No workaround exists.
Think of it like choosing between a quick taste test and a proper recipe comparison. The taste test is faster, but you’re less sure the winner will hold up when you serve it to 100 guests.
This trade-off is so fundamental that even clinical trials almost never use bandits. Routing patients to better treatments during the trial would literally save lives. Decades of research. Enormous incentive. And the medical world still uses equal allocation. Getting the right answer matters more than getting a fast one.
For your landing page, the stakes are lower. But the principle is the same. If you plan to run the winning version for months or years, spending a few extra weeks to be confident about the winner is a good investment.
CUPED and variance reduction techniques offer another way to speed up tests without sacrificing the quality of your results.
Should you use a bandit or an A/B test?
Skip the theory. Here’s the practical decision:
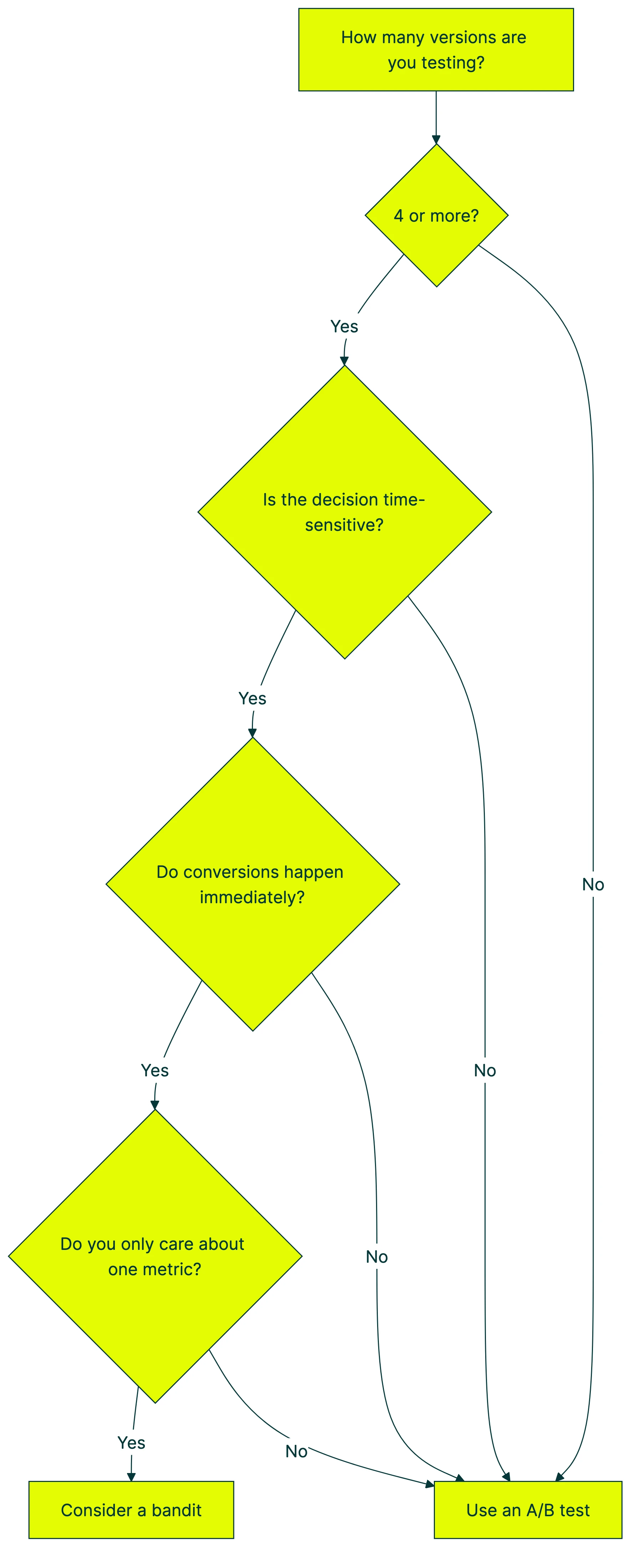
Use a bandit when all four conditions are true:
- You’re testing 4+ versions at the same time
- The decision expires soon (a promotion, a campaign, a headline that’s only relevant today)
- You see conversions immediately (clicks, opens, not purchases that happen next week)
- You care about exactly one metric
Use an A/B test when any of these are true:
- You want to understand WHY something works (not just pick the winner)
- You have 2-3 versions (which is most tests)
- You track multiple metrics (conversions, bounce rate, revenue per visitor)
- Conversions are delayed (SaaS trials, e-commerce checkout)
- You plan to apply what you learned to future tests
Use Kirro when you’re a small team that needs honest results fast. Bayesian statistics share the same mathematical family as bandit algorithms, but they preserve the ability to know if your results are real. You get speed without guessing.
Sven Schmit from Eppo nailed the distinction: “A bandit learns how to act optimally during data collection. An experiment collects data to enable complex analysis afterwards.”
Most businesses need the analysis. Most businesses should run A/B tests.
If you need help choosing what to test first, our guide on designing a marketing experiment walks through the process step by step.
What about Google? Didn’t they use bandits?
This comes up constantly. Google’s 2013 blog post about Content Experiments claimed bandits save “175 days on average” and “97.5 conversions” vs. classical A/B tests. Almost every bandit article on the internet cites it.
What those articles don’t mention: Google deprecated Content Experiments in 2019. Then they shut down Google Optimize entirely in 2023. The product that used bandits no longer exists.
Google’s internal experimentation teams now use advanced Bayesian methods. Not simple bandits.
This doesn’t mean the 2013 data was wrong. It means bandits worked for Google’s specific situation: large traffic, many versions, short-lived decisions. And even Google eventually moved past them.
When a tool vendor points to this blog post as proof that bandits are “just as statistically valid” as A/B tests, remember: they’re citing a discontinued product from over a decade ago.
How Kirro handles this differently
Most of the bandit problems come down to one thing: unequal traffic allocation messes with the statistics.
Kirro uses a Bayesian engine that shares mathematical DNA with Thompson Sampling (the most popular bandit algorithm). You get probability-based results that update as data comes in. Early signals without waiting for a fixed sample size. But traffic stays evenly split, so your results are actually trustworthy.
In practice, that means:
- You see “Version B has an 87% chance of being better” after a few hundred visitors, not just “needs more data”
- When there isn’t enough evidence, Kirro tells you honestly. No inflated confidence. No false winners.
- You can track multiple metrics at once, not just one
- Your minimum detectable effect stays reliable because the data isn’t contaminated by adaptive allocation
For most small teams testing headlines, buttons, and landing pages, this is the sweet spot. Faster than traditional A/B testing. More reliable than bandits. And you can set up your first test in about three minutes.
FAQ
What is multi-armed bandit testing in simple terms?
It’s an algorithm that automatically sends more visitors to the version of your page that’s converting better. Instead of a 50/50 split, it might send 70% to the version that looks like it’s winning and 30% to the other one. The split keeps adjusting as more data comes in. The name comes from slot machines (called “one-armed bandits”), and the “multi-armed” part means you’re choosing between multiple options.
Is multi-armed bandit testing better than A/B testing?
Not for most small businesses. Bandits reduce the number of visitors who see a losing version during the test. But they produce less reliable results, with false positive rates nearly doubling compared to standard A/B tests. For teams running 2-3 variant tests on their website, a good A/B test gives you more confidence and clearer insights. Bandits shine in specific situations: testing many variants at once, time-sensitive campaigns, and decisions where only one metric matters.
Is multi-armed bandit machine learning?
Yes, technically. Bandits are a type of reinforcement learning where the algorithm learns from outcomes and adjusts behavior. But you don’t need to understand machine learning to decide whether to use one. The important question isn’t “is this AI?” It’s “does this match my testing situation?” For most website tests, the answer is no.
What is the difference between multi-armed bandit and A/B testing?
An A/B test splits traffic equally and waits for a predetermined sample size to declare a winner. A bandit shifts traffic toward the better-performing version as data comes in. The trade-off: bandits waste less traffic on losers during the test. But A/B tests give you stronger evidence that the winner is real. A/B tests also let you measure multiple metrics. Bandits optimize for just one.
When should I use bandit algorithms instead of A/B testing?
When you’re testing 4+ options at the same time, the decision has a short shelf life (like a holiday promotion), conversions happen immediately, and you only care about one metric. That’s the sweet spot. For A/B testing tools that support bandits, look for ones that explain how they handle the statistical limitations. For everything else, stick with A/B testing. Simpler, more reliable, and you actually learn something for next time.

Randy Wattilete
CRO expert and founder with nearly a decade running conversion experiments for companies from early-stage startups to global brands. Built programs for Nestlé, felyx, and Storytel. Founder of Kirro (A/B testing).
View all author posts