The null hypothesis says your change made no difference. That’s it. When you run an A/B test, the null hypothesis is the default assumption that Version A and Version B perform the same. Your test’s job is to prove this assumption wrong.
Think of it like a courtroom. The null hypothesis is “innocent until proven guilty.” Your A/B test is the prosecution, presenting evidence. If the evidence is strong enough, the jury (your testing tool) rejects the null hypothesis and declares a winner. If it’s not strong enough? The verdict is “not guilty.” Not “innocent.” Just “we don’t have enough evidence to say otherwise.”
That distinction matters more than you think. Good testing methodology helps you avoid this trap. And most A/B tests never make it past the “not guilty” stage. You can check your own test results with the significance calculator or plan your next test’s visitor requirements with the sample size calculator.
What is a null hypothesis?
In plain language: the null hypothesis is your test’s starting position. It assumes your new headline, your new button color, your new pricing page layout did absolutely nothing. Zero impact. The test then looks at the data and asks, “Is there enough evidence to reject that assumption?”
If yes, your change probably worked. If no, you can’t say it did.
The concept goes back to 1925. A statistician named Ronald Fisher picked a threshold of 0.05 (5%) as a “rough rule of thumb”. If your data crosses that line, the evidence is “strong enough.” Not a scientific law. Not a magic number. A rough guide. This is the foundation of the frequentist statistical framework that most A/B testing tools still use today.
And somehow, a hundred years later, the entire testing industry still treats it like gospel.
A 2022 study found that only 9.4% of trained statisticians correctly interpret what the null hypothesis test actually tells you. Nine out of ten experts get it wrong. Imagine what the rest of us are doing with these numbers.
The court analogy is your best friend here. “Not guilty” doesn’t mean “innocent.” And “failing to reject the null hypothesis” doesn’t mean “your change had no effect.” It just means the evidence wasn’t strong enough to be sure. Maybe you needed more visitors. Maybe the effect was real but small. You just can’t prove it with the data you have.
Null hypothesis examples in A/B testing
Textbooks love coin flips and dice rolls. Let’s use real tests instead.
Headline test
You’re testing a new homepage headline against your current one.
- Null hypothesis (H0): “The new headline produces the same signup rate as the current one.”
- Alternative hypothesis (H1): “The new headline produces a different signup rate.”
- What rejection looks like: Your testing tool shows Version B with a higher conversion rate and enough confidence to rule out luck.
CTA button change
You changed your button from “Get started” to “Try it free.”
- H0: “Changing the button text has no effect on clicks.”
- H1: “The new button text changes the click rate.”
- What rejection looks like: Enough visitors clicked the new version to cross the confidence threshold your tool uses.
Pricing page testimonials
You added customer quotes to your pricing page. The null hypothesis says it doesn’t matter: “Adding testimonials has no effect on purchase rate.” If purchases go up enough to rule out random noise, you reject the null. The testimonials worked.
Email subject line
Two subject lines for your weekly newsletter. The null says they perform the same. You send each version to half your list, and the open rates diverge beyond what chance alone would explain. Null rejected. Ship the better subject line.
Notice the pattern. The null hypothesis always says “no difference.” The alternative always says “something changed.” Your A/B test collects the evidence and picks one.
These examples use simple A/B tests (two versions of one element). If you’re testing multiple changes at once, that’s multivariate testing, and the same null hypothesis logic applies. You just have more hypotheses running in parallel.
Every time Kirro tells you “Version B wins,” it has done the statistical heavy lifting behind the scenes. You just see the plain-English result. No math degree required.
Our take: You don’t need to remember the formulas. But understanding what your testing tool is actually doing makes you better at deciding when to trust the result and when to keep testing.
Null and alternative hypothesis: what’s the difference
The quick comparison:
| Null hypothesis (H0) | Alternative hypothesis (H1) | |
|---|---|---|
| What it says | No difference between versions | There is a difference |
| Role in the test | The default assumption | What the evidence must support |
| Burden of proof | Assumed true until rejected | Must be proven with data |
| Analogy | ”Innocent until proven guilty" | "The prosecution’s case” |
| When it wins | Not enough evidence of a difference | Strong evidence of a difference |
Some competitors frame the alternative hypothesis as “what you hope is true.” That’s dangerous. It encourages you to see what you want to see. Better to think of it as “what the evidence has to support.” You’re not hoping. You’re measuring.
Designing your test upfront matters a lot here. Write down both hypotheses before you look at any data. That’s called pre-registration, and it stops you from reverse-engineering a “win” after the fact. Place your bet before the dice roll, not after.
One-tailed vs two-tailed tests (quick version): A two-tailed test asks “is Version B different?” A one-tailed test asks “is Version B better?” Two-tailed is safer because it catches negative results too. If your test only looks for improvement, it might miss a change that’s actually hurting you.
How hypothesis testing works in A/B tests
Back to the court analogy. The whole process plays out like a trial:
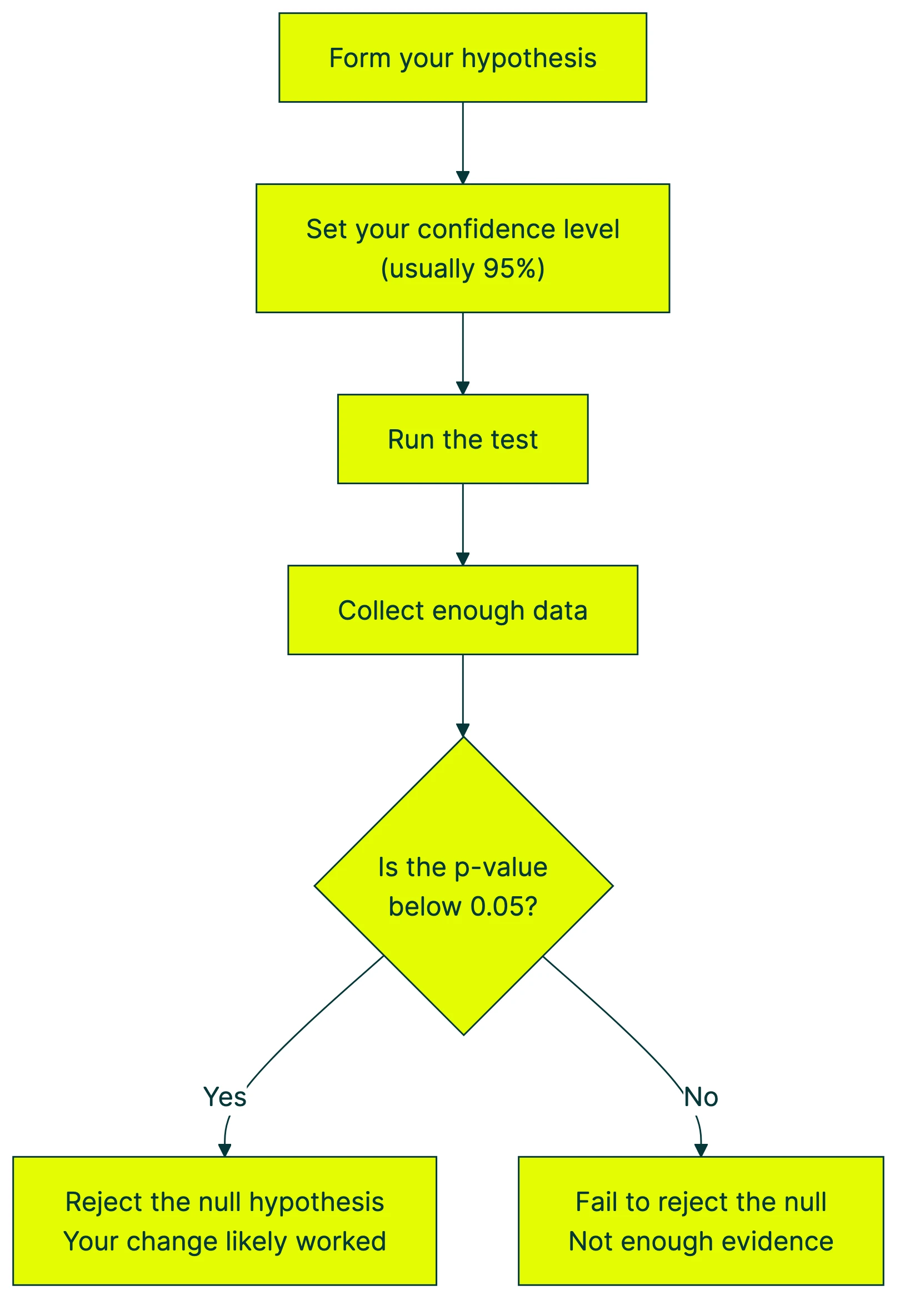
Step 1: Form your hypothesis. Write down what you’re testing. “Changing the headline will affect the signup rate.” The null hypothesis says it won’t.
Step 2: Set your confidence level. This is how sure you want to be before calling a winner. The standard is 95%, meaning you accept a 5% chance of being wrong. That 5% threshold comes from Fisher’s 1925 “rough rule of thumb.” It stuck around, not because it’s perfect, but because everyone agreed to use it.
Step 3: Run the test and collect data. Send traffic to both versions. The more visitors, the more reliable your results. This is where your sample size formula matters.
Step 4: Calculate the p-value. The p-value answers one specific question: “If there were truly no difference, how likely would I see data this extreme?” You can calculate the p-value yourself or let your testing tool handle it. A p-value of 0.03 means there’s a 3% chance of seeing results like yours if nothing actually changed.
The p-value does NOT tell you the probability that your hypothesis is true. Almost everyone gets this wrong. The American Statistical Association said it directly in 2016: “P-values do not measure the probability that the studied hypothesis is true.”
Step 5: Make a decision. If the p-value is below your threshold (usually 0.05), you reject the null hypothesis. Your change probably made a real difference. If it’s above 0.05, you fail to reject. Not enough evidence.
There’s a completely different way to do this. Instead of asking “how likely is this data if nothing changed?” you ask “what’s the probability that Version B is actually better?” That’s Bayesian A/B testing. It gives you a direct probability instead of a roundabout p-value. A lot of people find it easier to act on.
Our take: The p-value system isn’t broken, but it’s confusing enough that even experts misread it. If your testing tool gives you a straight “87% chance Version B is better,” that’s easier to act on than “p = 0.04.”
Why most A/B tests fail to reject the null hypothesis
This is the part nobody tells you. The null hypothesis isn’t just a theoretical starting point. For most tests, it’s the correct answer.
Ron Kohavi ran experimentation at Microsoft and Amazon. He published data in the Harvard Business Review showing that only 10-20% of A/B tests at Google and Bing produce positive results. At Microsoft broadly, the split is roughly thirds: one-third improve the metric, one-third do nothing, and one-third actually make things worse.
Let that sink in. At Google. With teams of hundreds of engineers and data scientists. Two out of three tests either do nothing or hurt performance.
A 2022 study from Wharton looked at 4,964 real A/B tests on Optimizely. The finding? Roughly 70% of tested effects are truly null. No real difference. The change just doesn’t matter.
So what does this mean for you?
Most of your test ideas won’t work. That’s not failure. That’s how testing works. The value isn’t in winning every test. The value is in finding the 10-20% of changes that actually move the needle, and not accidentally shipping the third that make things worse.
In our experience with landing page split testing, the tests that win tend to be the bolder ones. Not a new font size. A completely different headline. A new offer structure. A rewritten hero section. The bigger the change, the easier it is for the test to detect a difference.
A test that “fails” to reject the null hypothesis saved you from making a change that wouldn’t have helped. Or worse, would have hurt. That’s not a waste. That’s the whole point.
If you want to increase your odds, focus on bigger changes. Small tweaks (a slightly different shade of blue, moving a button 20 pixels) rarely produce detectable effects. You need a large enough minimum detectable effect to actually show up in the data. And your test needs enough statistical power to find it.
Common mistakes when testing the null hypothesis
Peeking at results before the test is done
This is the biggest one. You start a test on Monday, check the dashboard on Wednesday, see “Version B is winning by 15%,” and stop the test. Congratulations, you probably just found a false winner.
Netflix ran simulations and found that 70% of continuously monitored tests show false significance when no real difference exists. Evan Miller showed the same thing with smaller numbers: check results after every 150 visitors, and your false positive rate jumps from 5% to 26.1%.
That means one in four “winners” is fake. Not because the math is wrong, but because you looked too early.
And a Wharton study found that 73% of testers stop their test at the exact moment results hit their confidence threshold. That’s not testing. That’s waiting for the answer you want.
If you want to peek at results safely while a test runs, methods exist for that (called sequential testing). But the standard approach? Pick your sample size beforehand. Run the test until you hit it. Then look.
Treating 0.05 as a magic number
The 5% significance threshold is everywhere. But it’s not sacred. Fisher himself called it a rough guideline. The American Statistical Association’s 2019 follow-up went further. They called for abandoning the term “statistical significance” entirely. 43 supporting papers backed that recommendation.
A p-value of 0.049 crosses the line. A p-value of 0.051 doesn’t. But the difference between those two results is practically nothing. The test result didn’t change. Only your interpretation did.
Confusing “not significant” with “no effect”
Failing to reject the null hypothesis does not mean the change had no effect. It means your test didn’t have enough evidence to detect one. Maybe the effect is real but small. Maybe you didn’t have enough visitors. An underpowered test is like trying to see stars through a cloudy sky. The stars are there. You just can’t see them.
Statistical power is the fix. If your test doesn’t have enough visitors to detect the size of effect you’re looking for, “not significant” is almost meaningless. Our guide to A/B testing mistakes covers more ways this goes sideways.
Running too many tests on the same data
Every metric you check gives you another shot at a false positive (a result that looks real but isn’t). Test your headline against five metrics at once, and your odds of finding at least one “winner” by pure chance jump from 5% to 23%. That’s just the math.
That Wharton study found something worse. At the standard 5% significance level, 1 in 5 “significant” A/B test results is actually a false discovery. One in five. Across 4,964 real tests on a major platform.
Bayesian A/B testing handles some of these issues differently. Instead of a binary “significant or not,” it gives you a probability that Version B is better. No threshold drama.
Our take: The peeking problem alone has probably generated more wrong business decisions than any other testing mistake. Pick your sample size before you start. Run the test until you hit it. Then look. If you want to check early, set up your test with Kirro and let the tool tell you when results are ready.
FAQ
What is a null hypothesis in simple terms?
The null hypothesis is the assumption that nothing changed. When you run an A/B test, it assumes your new version performs the same as the old one. The test tries to prove this assumption wrong by collecting enough evidence (visitor data) to show the difference isn’t just luck.
What is an example of a null hypothesis?
Say you’re testing a new homepage headline. The null hypothesis would be: “The new headline produces the same signup rate as the old headline.” If your test shows Version B gets 4.2% signups versus Version A’s 3.1%, and there’s enough data to rule out chance, your testing tool rejects the null hypothesis and declares Version B the winner.
How does null hypothesis relate to A/B testing?
Every A/B test is a null hypothesis test. When you split your traffic between two versions, your testing tool checks whether the difference between them is big enough to rule out luck. If it is, the tool rejects the null hypothesis and shows you a winner. If it’s not, the null stands. Tools like Kirro handle all of this for you behind the scenes. You see plain-English results.
What happens when you reject the null hypothesis?
You’ve found enough evidence that your change made a real difference. But “reject” doesn’t mean “certain.” At a 95% confidence level, there’s still a 5% chance you’re wrong (that’s called a type 1 error). Think of it like a jury verdict: “guilty beyond reasonable doubt” still leaves room for error, just not much.
What is the difference between null and alternative hypothesis?
The null hypothesis says “no difference.” The alternative says “there is a difference.” The null is the default starting point (like “innocent until proven guilty”). The alternative is what the evidence has to support. You don’t prove the alternative by wanting it to be true. You prove it with data.
Can you prove the null hypothesis is true?
No. You can only fail to reject it. A court can say “not guilty” but never “definitely innocent.” Same thing here: a test can say “not enough evidence” but never “there is definitely no difference.”
A test that fails to reject the null might just need more visitors. Or the effect might be real but too small to detect. Failing to reject doesn’t mean nothing happened. It means you can’t be sure.
Now go test something
That’s the system working. It protects you from shipping changes based on luck. It forces you to collect real evidence before declaring a winner.
The traps? Peeking too early, misreading “not significant,” and treating 0.05 like a law of physics. Skip those, and you’ll get more out of every test you run.
Want to run your first test? Start by framing your change as a proper hypothesis with our A/B test hypothesis generator. Then pick one thing on your homepage that bugs you. Change it. Split the traffic. Let the data decide. The null hypothesis will either fall or hold. Either way, you’ll know more than you did before.
And knowing beats guessing. Every time.

Randy Wattilete
CRO expert and founder with nearly a decade running conversion experiments for companies from early-stage startups to global brands. Built programs for Nestlé, felyx, and Storytel. Founder of Kirro (A/B testing).
View all author posts